Empty Message
Sunday, January 23, 2022
Monday, January 10, 2022
How To Get All Columns In Group By
We can group the resultset in SQL on multiple column values. All the column values defined as grouping criteria should match with other records column values to group them to a single record. Most of the time, group by clause is used along with aggregate functions to retrieve the sum, average, count, minimum or maximum value from the table contents of multiple tables joined query's output.
Expression_n Expressions that are not encapsulated within an aggregate function and must be included in the GROUP BY Clause at the end of the SQL statement. Aggregate_function This is an aggregate function such as the SUM, COUNT, MIN, MAX, or AVG functions. Aggregate_expression This is the column or expression that the aggregate_function will be used on. There must be at least one table listed in the FROM clause. These are conditions that must be met for the records to be selected.

The expression used to sort the records in the result set. If more than one expression is provided, the values should be comma separated. ASC sorts the result set in ascending order by expression. DESC sorts the result set in descending order by expression. The number of records returned will never exceed the server's own limit, defined by the max_get_records_size parameter in the server configuration. Use output parameter has_more_records to see if more records exist in the result to be fetched, and input parameter offset & input parameter limit to request subsequent pages of results.

The default value is -9999.encodingstringSpecifies the encoding for returned records. Let us use the aggregate functions in the group by clause with multiple columns. This means given for the expert named Payal, two different records will be retrieved as there are two different values for session count in the table educba_learning that are 750 and 950. The group by clause is most often used along with the aggregate functions like MAX(), MIN(), COUNT(), SUM(), etc to get the summarized data from the table or multiple tables joined together. Grouping on multiple columns is most often used for generating queries for reports, dashboarding, etc. If a result_table name is specified in the input parameter options, the results are stored in a new table with that name--no results are returned in the response.

Both the table name and resulting column names must adhere to standard naming conventions; column/aggregation expressions will need to be aliased. Sorting will properly function only if the result table is replicated or if there is only one processing node and should not be relied upon in other cases. Not available when any of the values of input parameter column_names is an unrestricted-length string.

Group by is done for clubbing together the records that have the same values for the criteria that are defined for grouping. When a single column is considered for grouping then the records containing the same value for that column on which criteria are defined are grouped into a single record for the resultset. There's an additional way to run aggregation over a table. If a query contains table columns only inside aggregate functions, the GROUP BY clause can be omitted, and aggregation by an empty set of keys is assumed. The presence of HAVING turns a query into a grouped query even if there is no GROUP BY clause. This is the same as what happens when the query contains aggregate functions but no GROUP BY clause.

All the selected rows are considered to form a single group, and the SELECT list and HAVING clause can only reference table columns from within aggregate functions. Such a query will emit a single row if the HAVING condition is true, zero rows if it is not true. Function_nameFunction calls can appear in the FROM clause. When the optional WITH ORDINALITY clause is added to the function call, a new column is appended after all the function's output columns with numbering for each row. TtlSets the TTL of the table specified in result_table.chunk_sizeIndicates the number of records per chunk to be used for the result table.

Must be used in combination with the result_table option.create_indexesComma-separated list of columns on which to create indexes on the result table. Must be used in combination with the result_table option.view_idID of view of which the result table will be a member. The default value is ''.pivotpivot columnpivot_valuesThe value list provided will become the column headers in the output. Should be the values from the pivot_column.grouping_setsCustomize the grouping attribute sets to compute the aggregates. The attribute sets should be enclosed in paranthesis and can include composite attributes. Athena supports complex aggregations using GROUPING SETS, CUBE and ROLLUP.

GROUP BY GROUPING SETS specifies multiple lists of columns to group on. GROUP BY CUBE generates all possible grouping sets for a given set of columns. GROUP BY ROLLUP generates all possible subtotals for a given set of columns. Complex grouping operations do not support grouping on expressions composed of input columns. Once the rows are divided into groups, the aggregate functions are applied in order to return just one value per group. It is better to identify each summary row by including the GROUP BY clause in the query resulst.

All columns other than those listed in the GROUP BY clause must have an aggregate function applied to them. ROLLUP is an extension of the GROUP BY clause that creates a group for each of the column expressions. Additionally, it "rolls up" those results in subtotals followed by a grand total. Under the hood, the ROLLUP function moves from right to left decreasing the number of column expressions that it creates groups and aggregations on. Since the column order affects the ROLLUP output, it can also affect the number of rows returned in the result set. The UNION operator computes the set union of the rows returned by the involved SELECT statements.
A row is in the set union of two result sets if it appears in at least one of the result sets. The two SELECT statements that represent the direct operands of the UNION must produce the same number of columns, and corresponding columns must be of compatible data types. Aggregate functions, if any are used, are computed across all rows making up each group, producing a separate value for each group. When a FILTER clause is present, only those rows matching it are included in the input to that aggregate function. This syntax allows users to perform analysis that requires aggregation on multiple sets of columns in a single query.

It is not permissible to include column names in a SELECT clause that are not referenced in the GROUP BY clause. The only column names that can be displayed, along with aggregate functions, must be listed in the GROUP BY clause. Since ENAME is not included in the GROUP BYclause, an error message results.
If specific tables are named in a locking clause, then only rows coming from those tables are locked; any other tables used in the SELECT are simply read as usual. A locking clause without a table list affects all tables used in the statement. If a locking clause is applied to a view or sub-query, it affects all tables used in the view or sub-query.
However, these clauses do not apply to WITH queries referenced by the primary query. If you want row locking to occur within a WITH query, specify a locking clause within the WITH query. In general, UNBOUNDED PRECEDING means that the frame starts with the first row of the partition, and similarly UNBOUNDED FOLLOWING means that the frame ends with the last row of the partition . The value PRECEDING and value FOLLOWING cases are currently only allowed in ROWS mode.

They indicate that the frame starts or ends with the row that many rows before or after the current row. Value must be an integer expression not containing any variables, aggregate functions, or window functions. The value must not be null or negative; but it can be zero, which selects the current row itself.

In this case, the server is free to choose any value from each group, so unless they are the same, the values chosen are nondeterministic, which is probably not what you want. Furthermore, the selection of values from each group cannot be influenced by adding an ORDER BY clause. Result set sorting occurs after values have been chosen, and ORDER BY does not affect which value within each group the server chooses. Disabling ONLY_FULL_GROUP_BY is useful primarily when you know that, due to some property of the data, all values in each nonaggregated column not named in the GROUP BY are the same for each group. All the expressions in the SELECT, HAVING, and ORDER BY clauses must be calculated based on key expressions or on aggregate functions over non-key expressions .

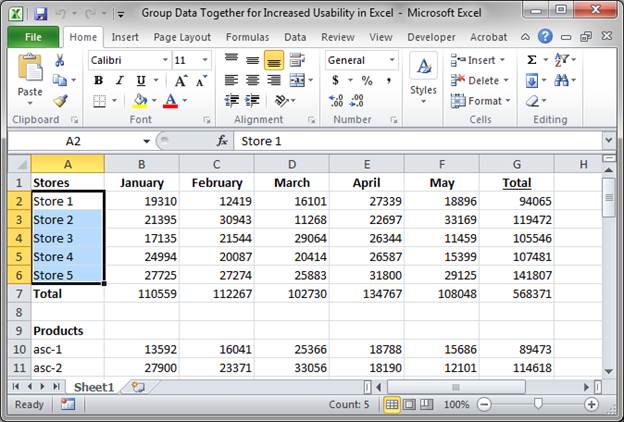
In other words, each column selected from the table must be used either in a key expression or inside an aggregate function, but not both. A functional dependency exists if the grouped columns are the primary key of the table containing the ungrouped column. If the WITH TOTALS modifier is specified, another row will be calculated. This row will have key columns containing default values , and columns of aggregate functions with the values calculated across all the rows (the "total" values). In the sample below, we will return a list of the "CountryRegionName" column and the "StateProvinceName" from the "Sales.vSalesPerson" view in the AdventureWorks2014 sample database. In the first SELECT statement, we will not do a GROUP BY, but instead, we will simply use the ORDER BY clause to make our results more readable sorted as either ASC or DESC.
FILTER is a modifier used on an aggregate function to limit the values used in an aggregation. All the columns in the select statement that aren't aggregated should be specified in a GROUP BY clause in the query. Adding a HAVING clause after your GROUP BY clause requires that you include any special conditions in both clauses. If the SELECT statement contains an expression, then it follows suit that the GROUP BY and HAVING clauses must contain matching expressions. It is similar in nature to the "GROUP BY with an EXCEPTION" sample from above.

In the next sample code block, we are now referencing the "Sales.SalesOrderHeader" table to return the total from the "TotalDue" column, but only for a particular year. Like most things in SQL/T-SQL, you can always pull your data from multiple tables. Performing this task while including a GROUP BY clause is no different than any other SELECT statement with a GROUP BY clause. The fact that you're pulling the data from two or more tables has no bearing on how this works. In the sample below, we will be working in the AdventureWorks2014 once again as we join the "Person.Address" table with the "Person.BusinessEntityAddress" table. I have also restricted the sample code to return only the top 10 results for clarity sake in the result set.

GROUP BY will condense into a single row all selected rows that share the same values for the grouped expressions. An expression used inside a grouping_element can be an input column name, or the name or ordinal number of an output column , or an arbitrary expression formed from input-column values. In case of ambiguity, a GROUP BY name will be interpreted as an input-column name rather than an output column name. Use theSQL GROUP BYClause is to consolidate like values into a single row. The group by returns a single row from one or more within the query having the same column values.

Its main purpose is this work alongside functions, such as SUM or COUNT, and provide a means to summarize values. The GROUP BY clause is used in a SELECT statement to group rows into a set of summary rows by values of columns or expressions. Pandas comes with a whole host of sql-like aggregation functions you can apply when grouping on one or more columns. This is Python's closest equivalent to dplyr's group_by + summarise logic. Here's a quick example of how to group on one or multiple columns and summarise data with aggregation functions using Pandas. Another extension, or sub-clause, of the GROUP BY clause is the CUBE.

The CUBE generates multiple grouping sets on your specified columns and aggregates them. In short, it creates unique groups for all possible combinations of the columns you specify. For example, if you use GROUP BY CUBE on of your table, SQL returns groups for all unique values , , and . The SUM() function returns the total value of all non-null values in a specified column. Since this is a mathematical process, it cannot be used on string values such as the CHAR, VARCHAR, and NVARCHAR data types. When used with a GROUP BY clause, the SUM() function will return the total for each category in the specified table.
IIt is important to note that using a GROUP BY clause is ineffective if there are no duplicates in the column you are grouping by. When using the AdventureWorks2014 database and referencing the Person.Person table, if you GROUP BY the "BusinessEntityID" column, it will return all 19,972 rows with a count of 1 on each row. A better example would be to group by the "Title" column of that table. The SELECT clause below will return the six unique title types as well as a count of how many times each one is found in the table within the "Title" column.

In the SQL-92 standard, an ORDER BY clause can only use output column names or numbers, while a GROUP BY clause can only use expressions based on input column names. Another difference is that these expressions can contain aggregate function calls, which are not allowed in a regular GROUP BY clause. They are allowed here because windowing occurs after grouping and aggregation. However, you can use the GROUP BY clause with CUBE, GROUPING SETS, and ROLLUP to return summary values for each group.
All output expressions must be either aggregate functions or columns present in the GROUP BY clause. Grouping_expressions allow you to perform complex grouping operations. You can use complex grouping operations to perform analysis that requires aggregation on multiple sets of columns in a single query. The GROUP BY clause divides the rows returned from the SELECTstatement into groups.

For each group, you can apply an aggregate function e.g.,SUM() to calculate the sum of items or COUNT()to get the number of items in the groups. The GROUP BY clause is often used with aggregate functions such as AVG(), COUNT(), MAX(), MIN() and SUM(). In this case, the aggregate function returns the summary information per group. For example, given groups of products in several categories, the AVG() function returns the average price of products in each category. The key of it all is the way that we can use the "grouped rows" to actually re-expand those rows and use the average of the whole dataset against every single row. If you had, for example, another fridge, then the technique will still work – you wouldn't need to change anything from the query itself.

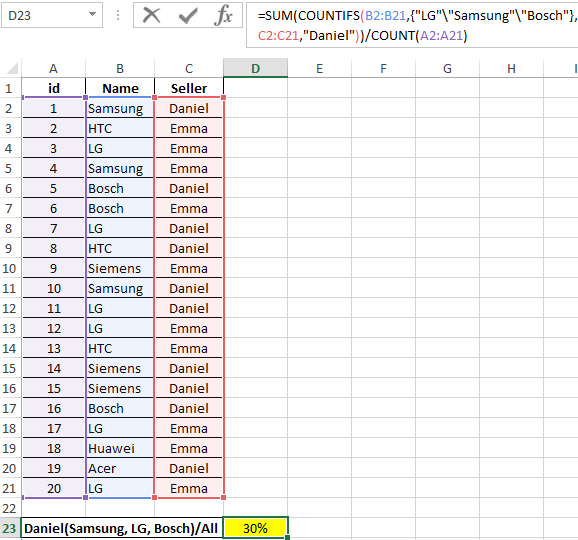
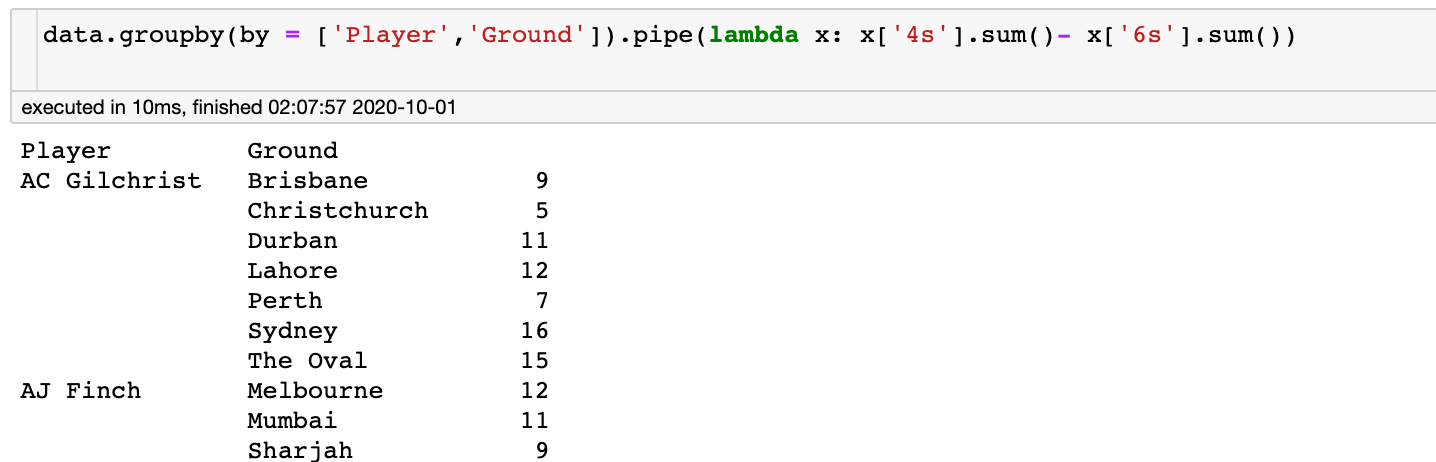
How Do I Get All Columns In A Group By We can observe that for the expert named Payal two records are fetched with session count as 1500 and 950 respectively. Note that the aggregate functions are used mostly for numeric valued columns when group by clause is used. Criteriacolumn1 , criteriacolumn2,…,criteriacolumnj – These are the columns that will be considered as the criteria to create the groups in the MYSQL query. There can be single or multiple column names on which the criteria need to be applied. SQL does not allow using the alias as the grouping criteria in the GROUP BY clause.

Note that multiple criteria of grouping should be mentioned in a comma-separated format. Aggregation is a process in which we compute a summary statistic about each group. Aggregated function returns a single aggregated value for each group.

After splitting a data into groups using groupby function, several aggregation operations can be performed on the grouped data. Contrary to what most books and classes teach you, there are actually 9 aggregate functions, all of which can be used with a GROUP BY clause in your code. As we have seen in the samples above, you can have a GROUP BY clause without an aggregate function as well. As we demonstrated earlier in this article, the GROUP BY clause can group string values also, so it doesn't always have to be a numeric or date value.

In the sample below, we will use the DATEPART function to return only the year from the "ModifiedDate" column of the "Sales.SalesTerritory" table along with the average amount due from the same table. The GROUP BY clause is normally used along with five built-in, or "aggregate" functions. These functions perform special operations on an entire table or on a set, or group, of rows rather than on each row and then return one row of values for each group. To prevent the operation from waiting for other transactions to commit, use either the NOWAIT or SKIP LOCKED option. With NOWAIT, the statement reports an error, rather than waiting, if a selected row cannot be locked immediately.

Subscribe to:
Comments (Atom)
How Do You Measure Volume Science
Volume is an amount of space, in three dimensions, that a sample of matter occupies. The number and the phase of the molecules in the sampl...

-
We can group the resultset in SQL on multiple column values. All the column values defined as grouping criteria should match with other reco...
-
Volume is an amount of space, in three dimensions, that a sample of matter occupies. The number and the phase of the molecules in the sampl...
-
Empty Message

